
Frequently Asked Questions
Sign Up:
- Can you list the services included in the subscription?
Free Services: (no login required)
(1) Free Daily Digests incl. arXiv daily, bioRxiv daily, and medRxiv daily
(2) Literature Search search 300M records across papers, patents, grants, clinical trials, venues and software
(3) Access to all paper digest articles incl. conference digest, “best paper” digest, trending topics, etc.
(4) Access to some paid services with a daily quota
Paid Services: (all included in the subscription)
(5) Daily Digest our most popular service – keep track of the latest papers, news, posts, clinical trials, etc. We cover major academic sites like arXiv, PubMed, bioRxiv, medRxiv, clinicaltrials.gov and thousands of conferences and journals.
(6) Literature Review review the most influential work around any topic by area, genre & time
(7) Research Copilot help you on coding and other tasks through dialog
(8) Academic Writing help you write, edit and cite sentence by sentence
(9) Academic Reading ask pdf type service: get answers and insights from your own data
(10) Question Answering get answers & insights from the scientific literature by area, venue & time
(11) Deep Research get in-depth analysis for any research topic
(12) Journal & Conference Digest Console browse, search, review & research by venue
(13) Research Libraries organize docs / pdfs, add tags, take notes & share with others
- How much does it cost to subscribe to Paper Digest paid services?
You’ll find our prices are among the lowest in the industry.
(1) We currently offer three pricing plans for new users to sign up: $6.66 USD/Month ($79.90 USD billed every 12 months), $7.99 USD/Month ($47.94 USD billed every 6 months) and $10.99 USD/Month (billed every month).
(2) We also offer a one-time payment option to get the services for a fixed period of time: 6 Months (one-time payment of $47.94 USD). This option mainly serves the users whose cards do not support US dollars or recurring payments.
(3) The above prices do not apply to the existing accounts.
- If I do not receive the email confirmation after making the payment, what should I do?
After you create an account, you should immediately receive an email confirmations from us (with login information). If you do not receive the confirmation in 1 hour and have already checked the junk/spam folder, then please contact us at team@paperdigest.org. It is possible that our emails sending to you were blocked by your email service provider, so please also include a different email address so that we can send the reply to both addresses.
- I probably signed up with a wrong email, what should I do?
Please contact us at team@paperdigest.org. In your email, please tell us the time when you signed up and what payment method you used to sign up.
- Can I update my preferences after signup?
You can visit “Account | Update Interests” after signing in to update your name, affiliation, interests, preferences to receive daily digests and keywords/authors to follow. The only thing that cannot be updated is Email, which serves as your account ID.
- Where can I see my account expiration date?
After signing in, check out the Account | User Information page. You will find the account expiration date there. If your account is on an active monthly/yearly plan, there is no expiration date.
- How to renew the one-time payment option (e.g. the 6-month plan)?
The 6-month plan is designed for users whose credit cards do not support US dollars or recurring payments. When you subscribe to the 6-month plan, we will create an account using your email, and the account is set to expire in 6 month. Before your account expires, you can use the same email to subscribe again, which will extend your previous expiration date by 6 months. If you subscribe again after your current account has expired, we will create a new account for you.
- Can I try your services before signing up?
To help users set the right expectations on what our services can do, we encourage every user to try our services for free before signing up. In fact, almost all our existing paid users tried our services before making the payment. There is a limit on free daily quota of 5 review / 10 rewriting / 10 question-answering jobs. Once the daily limit is reached, one can come back in 24 hours to keep trying the services. If one needs more jobs to be processed in a single day, one needs to subscribe to our paid membership, and use our services with no daily limit.
Cancellation & Refund Policies:
- What is your cancellation policy, refund policy and how to cancel the subscription?
Your payment method will be charged at the beginning of each billing cycle unless you cancel before then. To avoid future charges, please cancel the subscription before the end of the current billing cycle. We also send out a reminder email 7 days before the renewal date. The monthly/half-yearly/yearly subscriptions can be canceled at any time to stop all future payments via the “close account” link. The account will remain valid till the end of the current billing cycle and then be permanently closed. The one-time payment option (e.g. the 6-month plan) does not offer the cancellation choice, since it will automatically expire in 6 months. Paper digest subscriptions are non-refundable, and Paper Digest will not prorate any fees paid for a subscription that is terminated before the end of its term. For the extremely uncommon situation where an account’s activity violates our terms of use or the law, the account will be terminated before the end of the billing period, and no refunds will be issued.
If you intended to cancel the service but narrowly missed the deadline, or have further questions / special requests related to cancellation, refund, etc., please contact us directly via email (team@paperdigest.org). We will try our best to help.
Payment:
- Is your online payment system secure?
As hundreds of thousands of other websites, we use Stripe.com and Paypal as our online payment systems. Paper Digest also maintains an internal security system to monitor unusual user activities. To ask payment related questions or learn more about our payment fraud detection efforts, please email us (team@paperdigest.org).
- How can I update my payment method?
You can also let us know via email (team@paperdigest.org), we will reply with a link that you can follow to update your payment method.
- How does the recurring payment work?
(1) Most of our users are on monthly, half-yearly or yearly plans. We authorize Stripe to charge the membership fees on behalf of us at the beginning of each billing cycle. A user will receive a receipt if the payment is successful. The receipt mainly serves as a reminder for users to remind them that they are still paying for our service.
(2) If one wants to cancel the service, please cancel it before the end of the current billing cycle to avoid being charged for the next billing cycle. For example, if one created the account on Jan 15, the next billing cycle will start on Feb 15. In fact, we will keep the account valid till the end of the current billing cycle after cancellation. If one only wants to use the service for a couple of days, one can cancel the service immediately after signing up to avoid future charges.
(3) If the recurring payment fails for some reasons, the associated accounts will be deactivated automatically. If the affected users still wants to keep the account, please send us an email (team@paperdigest.org) to address the payment issue. Users can also choose to create new accounts (it is fine to use the same emails).
- The system says the account that I have been using does not exist or has been deactivated. What happened to my account?
It typically means that the account has been temporally closed. The most common reason for this is that Stripe cannot collect monthly/yearly payments from the account. Affected users can contact us to address the payment issue or simply create a new account (it is fine to use the same email).
Account Management:
- I forgot my password, how to recover it?
Password can be recovered using the following button:
- How to change my current password?
Password can be changed within the console under “Account | Change Password” or using the following button:
- I do not want to receive daily digest emails any more but still like to receive conferences digests and keep access to the other services/resources, what can I do?
The simplest way to disable daily emails is to click on the “unsubscribe” link at the end of each email. You can also disable/re-enable the daily digest service using the button shown below. If daily digest service is disabled, you will not receive daily digest emails any more. You will still be able to read daily digests through our console. The service can be easily re-enabled using the same link. The service can be updated within the console as well (under “Account | Enable/Disable Daily Email”).
- Can I share my account with my collegues?
Sharing accounts is not allowed. Engaging in this activity will lead to the suspension of accounts, and all associated machines or IP addresses involved in such an activity will be barred from accessing our services.
- Why does my account become “deactivated”?
There are several reasons why an account can be deactivated:
(1) Stripe cannot collect monthly/yearly payments from the account.
(2) When a recipient of our emails clicks the “Spam” button (or its equivalent, such as “junk”, “block”, “reject” buttons) in their email application, their email service provider (such as Yahoo, QQ, etc.) may send a warning message to us indicating this recipient has marked our emails as Spam. When we receive such emails, we will deactivate the complaining recipients to make sure such users will not be in your future email sends. The deactivation typically goes into effect within 24 hours.
(3) If our emails sent to a user are bounced back multiple times, the associated account will be deactivated.
(4) Policy violations. For example, the account is found to be associated with prohibited activities like account sharing (multiple people share one account), fraudulent transactions, etc.
If an account is deactivated, it will not be able to log in to the console, and the future payments will be stopped. All deactivated accounts will be permanently deleted every few months. To continue using the service, affected users will have to create new accounts, or contact us to restore the previous accounts before they are permanently deleted.
System:
- How to check service status?
If your internet speed is low, you may see page hang up occasionally. This can be addressed by refreshing the page (F5) or making a hard refresh (Ctrl+F5). You can also check the service status using the following button:
- Do you send out digests every day?
Digests are sent out Monday-Friday.
- Why my IP is blocked?
If suspicious activities are detected, we will block the related IP addresses. Affected users may contact us to explain what happened to lift the restrictions.
- I can see daily paper digests using the console, but never received any daily digest email, what happened?
Probably when you registered the service, you chose to disable the daily digest service. You can re-enable the service using the following button:
It is also possible that emails sent to you are put in spam folder, or blocked by your email service providers. You can mark our digests as “not spam”, and whitelist us.
- I do not receive daily digest emails on some weekdays, what happened?
There are several possible reasons:
(0) If a user does not select any interested area, then we will not send out daily emails. We allow users to specify keywords they are interested in during the signup process. At this moment, such keywords are only being used to generate daily digests if interested areas are also specified.
(1) If the areas you signed up are not very active, then it is normal that you do not receive updates everyday.
(2) The paper websites that we are tracking (like arxiv.org) may not release new papers in time due to holidays or outages. Once their services are back to normal, our users will be able to access the digests through paper digest console. We will not send out digest emails if the delay is longer than half a day, but will notify users about the issue in the next daily digest emails. Such scenarios do not happen very often (1-2 times per year).
(3) Emails sent to you have been blocked by your email service provider. If emails sent to a user are bounced back multiple times, we will have to disable the associated account. If a large number of emails sent to a domain are bounced back, we will have to limit #emails we can send to that domain. We notice that users using emails from qq.com and 163.com experience this problem more frequently than the others.
(4) Universal Solution: Users can login to the console and read digests under “Digest | My Daily Digest”, which provides the same contents as email sent outs.
Daily Digest:
- How do you decide what papers will be included in my daily digest?
(1) When a user creates an account, we asked the user to select at least 1 out of >200 research areas. Our default setting is to push all new papers under the selected area(s) to the user. A typical user receives dozens of papers on a daily basis.
(2) We allow users to select keywords and authors to track: users can key in the keywords or authors’ names using Account|Update Interests. Users can also click on follow this author on an author’s profile page or i-Search page. Papers that can pass those filters are called “tracking results” and will be put on top of each daily digest email (marked with *).
(3) Users can decide the best way to get notified. The default setting is to receive a daily digest email if there are new papers under the area(s) that the user signed up with. Users can also choose to receive the daily digest email only when tracking results are available. We also allow users to completely disable the daily digest email and read the digests online.
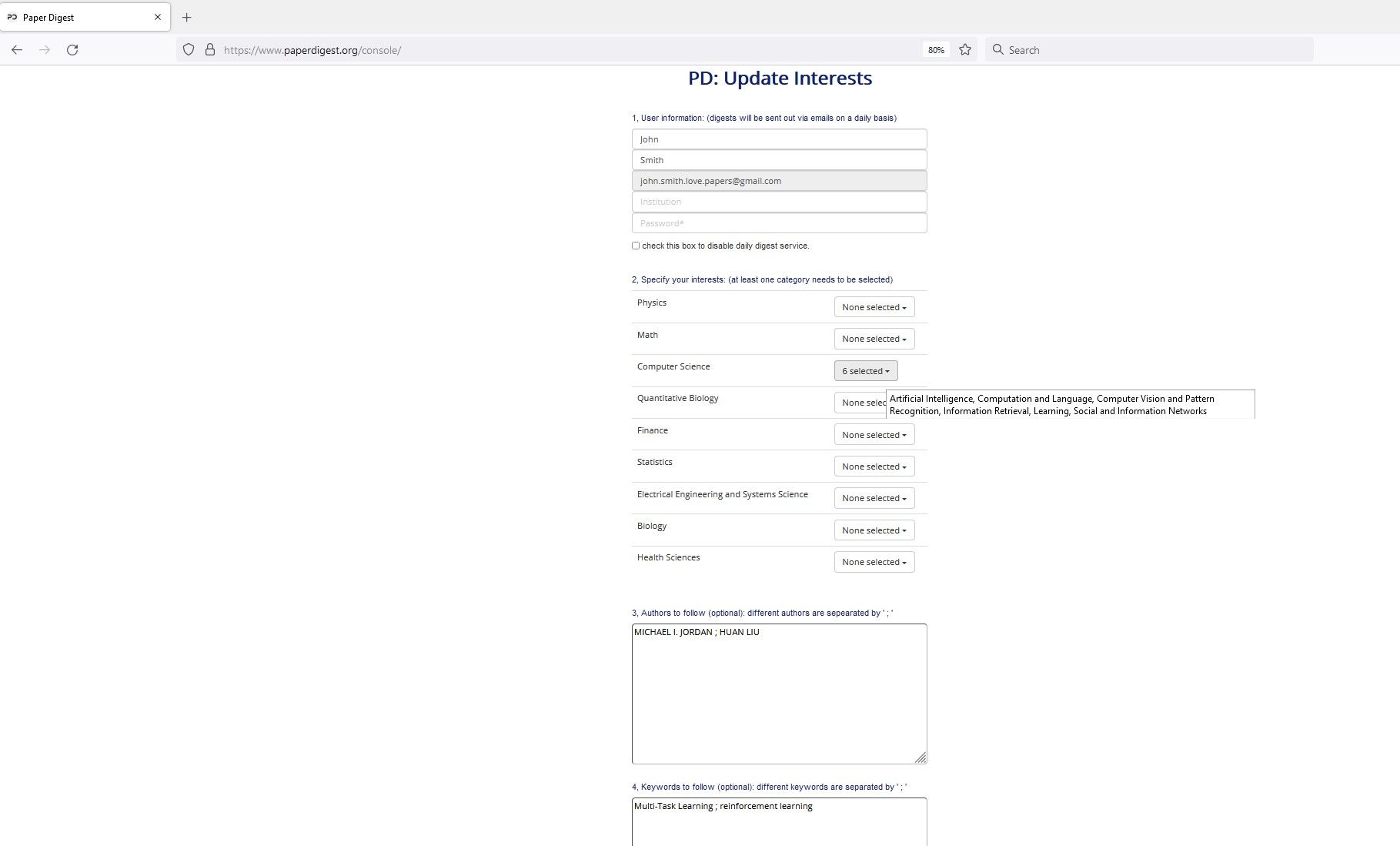
- How to update my interests & author/keyword tracking list?
Such information can be updated at “Account | Update Interests” (login required). Note: “email” is not editable. Here is an example: John Smith’s update interests page.
{kind=link}
- I get digests for more than 200 papers everyday, and I cannot read all of them. How can I receive fewer?
Short Answer: If you only have time to browse n papers, then just browse the top n papers on the daily digest console. We have an algorithm that can estimate the potential impact of each new paper. The daily digest results on the console are sorted based upon the potential impact.
Other Solutions: Some areas are active like ‘cs.AI’, so it is expected to see a lot of new papers everyday when multiple such active areas are selected. The problem gets worse in January-March, since deadlines of many conferences fall in this time range. Other than the short answer mentioned above, we think the following alternate solutions may also help:
(1) We always encourage users to narrow down the selected interests (see How to update my interests & author/keyword tracking list?). With fewer interests selected, users get fewer updates.
(2) Papers can be sorted by primary category, readers can decide what papers to read based on categories if he/she does not have time to read all.
(3) We have a console for users to filter out papers that they are not interested in. Users can login the console, and then click on “Digest | My Daily Digest”. This returns a list of links to all daily digests in the last two weeks. The contents here are the same as what we sent out in daily digest emails. For each day, one can choose to read new papers only, updates to previous papers, or both. Users can also sort papers based on columns and type in a keyword in “filter” field to only show papers with the desired keyword.
(4) We encourage users to specify authors & keywords to track (see “Account | Update Interests”). Users can login the console, and then click on “Digest | My Daily Digest | Tracking Results”. This returns a list of papers that are either published by the authors in the tracking list or are associated with keywords in the tracking list. This will significantly decrease the number of daily papers to browse. For most users, setting author/keyword filters can decrease the number of daily papers to a single digit. Users can also choose to only receive papers by the selected authors or with the selected keywords.
- Precisely, what is a “highlight”?
By our definition, a highlight is a sentence that can immediately tell readers what the paper is about. With such highlights, readers should be able to quickly browse a large number of papers, keep up with the most recent work and find the papers that they like to focus on.
- What does the number in your daily digest email title represent, for example, 0151832 in “Paper Digest-2020.09.08 0151832”?
It is a random number we purposely append to email title. As many of you know, some email service providers may block an email sender if that sender sends out a large number of emails with the same contents (bulk emails). Paper Digest has a large number of daily digest subscribers, and needs to send out a lot of emails on a daily basis. Even though our contents are customized for each individual and thus different, the email titles used to be the same (e.g. “Paper Digest- 2020.09.08”) for all subscribers. To lower the chance that our emails will be marked as spam or rejected, we append a random number to each email title to make titles look different.
- What is the difference between Daily Digest and Topic Tracking?
Daily digest emails are generated based on user selected categories/keywords/authors. There are more than 200 such categories in total, like artificial intelligence, computer vision. Topics in topic tracking typically have a much narrower coverage compared to user selected categories. We currently track ~60 topics, covering trending topics in Biology/Health, Computer Science, Finance, Math, and Physics. Depending on the demand, we may frequently add new topics and remove old topics. The categories in daily digests do not change very often.
Best Paper Digest:
- In “Best Paper” digests, how are the most influential papers selected?
“Best Paper” digests are created for top conferences/journals. All papers published on a given year are ranked based upon #paper citations + #patent citations. The ranking lists are also updated regularly to reflect the most recent changes.
- I have a paper with a lot of citations, but it does not appear in your “Best Paper” digests, may I know why?
There are several possible reasons:
(1) the papers in best paper digests have more citations.
(2) our system does not have all citations that you are aware of or our system does not associate citations to the right paper. For example, our system may fail to match a paper and its citations, when the paper title or author names contain foreign characters.
(3) feel free to let us know if you find any problem, we will look into it and get the problem fixed. All changes will go into the next updates.
Literature Review:
- Do I need an account to use the literature review service?
For the time being, this service allow users to generate up to 5 reviews each day without sign in. After that, users will be redirected to the signin page.
- When I clicked on submit button, I received a message “Our literature review service is busy, please try again in a minute.”. What should I do?
Literature review service requires a lot of resources: CPU, Memory, Bandwidth, etc. To avoid overloading the service, we set a limit on #users that we can simultaneously serve. Once the limit is reached, the system will reject further requests and pop up the service busy message. Users can wait for a minute and click the submit button again. Based on our statistics, the chance to see this message is low: under 0.1%.
- How much time should I wait to receive literature review results?
It depends. 99% results are dynamically generated. Typically, it takes 5-6 seconds. Sometime, it may take up to 10 seconds. We also cache some review results for a couple of hours. If the review result is already in cache, users should get it immediately. Cache is refreshed frequently (typically in hours) to guarantee the results are up to date.
- How can I share the literature review results with my colleagues?
Once you are happy with the review results, click on “share results” under the submit button. This will create a direct link that you can share with your colleagues.
- Will review results remain the same for a while?
The review results could be different from hours ago. More specifically, 99% reviews are dynamically generated to include the most recent research work. We do have a cache to store some review results, and the cache will be refreshed every few hours to include the up to date information.
Search Console:
- What is “IF” and how is it calculated?
“IF” stands for impact factor. It is a score in 1.0-10.0, calculated based on paper citations, patent citations, etc. A higher value indicates a broader impact. This is not the score used to rank “most influential papers”, which is ranked based on a much simpler metrics: #paper_citations + #patent_citations.
- What is the advantage of using your search console compared to using other academic search sites?
There are a couple of advantages:
(1) Most of our search results come with highlight sentences. This helps users quickly decide if a paper is worth reading or not. We are the first to provide this feature in industry, and able to offer high quality highlights for all subjects.
(2) Every paper in our result list is associated with related papers, patents, grants, experts and organizations. This feature is unique in industry.
(3) Author profiles of each paper are also provided. Users can click on author names and see their recent papers, grants and patents. Users can also follow some authors and get alerts on their new publications in daily digest emails.
Technologies behind Paper Digest:
- What technologies are you using to generate paper digest and search results?
We have a fairly complicated text analysis platform (comparable to the platforms developed & used by those largest tech corporations) to support scientific literature tracking, search, review and rewrite services.
The platform contains
(1) a central knowledegebase storing hundreds of millions of documents;
(2) a number of site crawlers tracking new research work in real-time;
(3) a pipeline with dozens of built-in natural language processing and machine learning components to analyze documents. For example, we have several different algorithms (from rule-based to transformer-based) for paper summary generation. We have been improving them over time with the most recent technologies.
- Can you explain how paper highlights are generated in detail?
Given a paper, our system first processes the paper to get the parse results. Then a set of candidate generation components start working on the parse results to generate highlight candidates. Different generation components are based on different strategies. For example, any single sentence in the paper can be generated as a candidate; adjacent sentences can be merged to a candidate; sentences connected by co-references can also be formed as candidates, etc. We usually generate a lot of candidates for each paper. After candidates are created, a set of scoring components will be applied to score each candidate from different perspectives. For example, some scorers are rule-based to check if the candidate has the desired patterns; some are deep learning based scoring candidates based on pre-trained neural networks; some model the location of candidates (from abstract, from conclusion, etc.); some check if the candidate aligns with the title well or not. We have dozens of such candidate generation and scoring components. Techniques used in some of these components are exclusive. Together these components assign each candidate with a set of features. In the last step, a final ranking model ranks all candidates using the features created in the previous steps and produces a confidence score for each candidate. We return the top candidate as the paper highlight if the confidence score is above a threshold. Depending on applications and data availability, we can choose what components to integrate in the pipeline.
- Are you using deep learning in your system?
Some of our components are based on neural networks. They are integrated in our pipeline system.
- Where do your highlight sentences come from?
This depends on what the input is. The input can be as long as a full paper or as short as title plus abstract. Highlight sentences can be created from anywhere in the input. Most of the time, we use title + abstracts as our input.
- Are you using large language models (LLM) like ChatGPT and LLAMA?
In the applications where AI “hallucinations” are highly problematic (e.g. literature review), we offer a solution that does not integrate any large language models (including our own) since their rate to generate unjustified results is surprisingly high even when context (e.g. web search results, user input PDFs) is given. In such applications, users will be able to decide if they want LLM to be used or not. If an application is LLM-based, we will make it crystal clear, since it could produce results with hallucinations. Our platform has integrated both our own LLMs and some 3rd party APIs including Google’s gemini and OpenAI’s chatgpt.
Others:
- What services do you provide?
You can see a list of services that we offer via the About Us link.
- Do you offer bug bounty programs?
We do not offer bug bounty programs.
- Is it possible for you to automatically generate lengthy articles?
To uphold academic integrity, our system restricts the generation of excessively lengthy text. The maximum length of text generated is approximately 2,000 English words through our Deep Research service. While we offer a service for composing lengthy articles, it is done in a sentence-by-sentence manner. Interested users can utilize our Academic Writer to write, edit & cite long articles.
- Who is running paperdigest.org?
We are a group of researchers and engineers working on machine learning and natural language processing.
- How to contact paperdigest.org?
All questions, requests and comments can be sent to team@paperdigest.org.